A Series of MongoPush Events
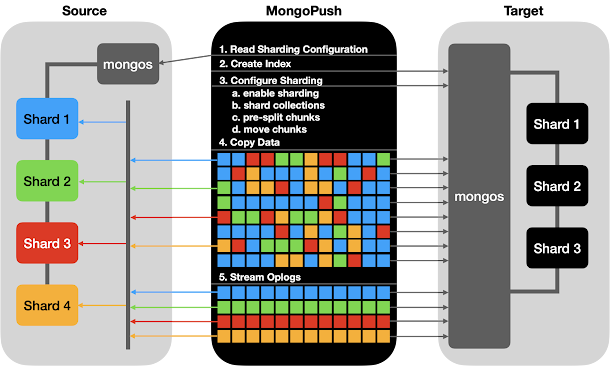
MongoPush is not only a data migration tool but also a database cluster transformation solution. Data migration is one of many functions mongopush has.
Another Bold Stroke
In my tenure at Professional Services, December has been a month full of customer requested cancellations and thus resulting in many last minute engagements. Right before the December holidays in 2020, I was assigned to an Atlas migration consultation on a short notice. A colleague of mine already demonstrated to the customer a replica set migration to Atlas using the mongomirror tool in a previous meeting. The customer asked me to use the same procedure and tool to mirror a 3-shard cluster to Atlas. Unfortunately, it was not possible to migrate a sharded cluster using a simple mongomirror command. After explaining the steps of migrating a sharded cluster using multiple modified mongomirror instances, the idea of simplifying the process of migrating sharded clusters began brewing in my head.
The mongomirror tool has accomplished its phased mission and it made Atlas live migration possible. But, continuous support to mongomirror has limited itself to its original frame with little modernizing, e.g. not even supporting SRV record connection strings Atlas uses. With Atlas expanding fiercely, this was my attempt to provide a modern tool that moves with the time. My colleague Daniele Graziani once encouraged me to add a live migration feature to my other tool Keyhole, but I shied away from adding additional functions to Keyhole at that time.
I took a week off right before New Year 2021 and originally planned to do nothing. In that week, every morning I played with my table tennis robot, and kept thinking of the customer’s comments on the lack of a proper migration tool when migrating data from behind a corporate firewall. With inspiration from the movie Miss Sloane (2016), Sloane quoted from Luke 14:10 and asked her staff to rise up and touch the glory. I decided to explore the possibility of creating an easy-to-use migration tool and hopefully to intrigue young bright talented engineers to improve Atlas migration tools. A Chinese idiom to better describe my intention is 拋磚引玉 (pāo zhuān yǐn yù), which literally means throwing away a brick to instigate others to throw a jade.

Think Outside The Box
My expectations for the new tool were 1) topology agnostic, 2) fast, 3) easy to use, and 4) with a visual progress report. The initial design is well documented in MongoPush - Push-Based MongoDB Atlas Migration Tool and many thanks to my friend Eoin Brazil, also an expert MongoDB engineer, for shaping my design into a fluent blog.
I began creating a PoC on my newly purchased Mac Mini, which finally had a chance to flex its muscle. During the development, I referenced my respectful colleague Mark Helmstetter’s “migrating a sharded cluster using a modified version of mongomirror” notes and my former colleague Shyam Arjarapu’s Java migration tool, migrate-mongo-cluster. It didn’t take me long to complete a PoC. I spent one hour playing ping-pong and thinking, and another hour writing codes everyday for a week. Because everything including tests were done on the Mac Mini locally, the target cluster was not required to be an Atlas cluster. At the completion of the PoC, it proved the ideas and design were doable.
Since day one, I have realized that without anyone using mongopush, it would be another software debris abandoned in the corner of the Internet. To avoid that I treated this development the same way as creating a consumer product. I was a big fan of the iPhone when it was first introduced. Other than the iPhone's innovation and features, it was an easy-to-use and stylish handset. Similarly, mongopush providing migration status and completion time forecasts improves the user experience and helps users monitor migration progress in preparation for cutover. Therefore, the idea of having a detailed visual progress report was included from the very beginning.
Furthermore, providing continuous improvement and support in a timely manner would encourage users’ adoption of mongopush. However, my resources and time were limited to test migrations thoroughly for different use cases with large amounts of data. The best I could do was to prolong the development time by staying out of sight and flying under the radar to make up for the lack of resources. For migration tests, many thanks to those early adopters for your efforts and having faith in my personal contribution. An APAC colleague, Sergio Castro, assisted testing in the early phase of development.
The name mongopush was from the fact that it pushed data to Atlas from behind corporate firewalls. The inspiration of the mongopush name was from the movie Something Borrowed (2011), where I heard Salt-N-Pepa’s Push it! when Rachel and Darcy danced to the song. The mongopush dude logo reflected my idea of pushing at full speed.
An Uphill Journey
The intention of throwing away a brick to get a jade backfired. It felt like I threw a brick into a lake. It made a splash like my very first bad springboard diving and the ripple effect was beyond my anticipation.
With a migration idea full of possibilities, I demonstrated the PoC to my colleagues and managers on a few occasions. Unlike Eoin’s positive support, responses were indifferent. After working with these top guns for a few years, I was not surprised. Many of them probably went back to their own toolboxes and looked for other possible solutions. One of the managers laughed so hard to reflect his authentic impression that he might have injured his back. The submission to publish the blog on mongodb.com had been forever ignored. I began doubting the need to fill the gap of Atlas migration tools and placed this project on a back burner the first time.
The first ambush was from a respectful Solution Architect mentioning mongopush to a broader audience intending to migrate from a global cluster in January 2021. At the time, mongopush was not battle hardened and my first reaction was a worse version of “oh, shoot!”. I began testing mongopush more just to prepare if people were ready to use it. In the end, the customer decided to roll their own solution and the project was put on a back burner again.
Soon after Valentine Day 2021, I struck off an item from my bucket list by adopting a puppy. Having to wake up early in the morning and stay in more I found myself with time to work on mongopush again. This sporadic effort lasted until Easter 2021 when Diana Esteves, a former colleague, decided to use mongopush for a complex customer migration project and provided me invaluable feedback. The databases and/or collections exclusions feature was her idea. With a clear target in my sights, mongopush began evolving into a migration tool that many migration projects couldn’t do without.

More and more users began finding out about mongopush and using it for their own use cases by Memorial Day 2021. After trying it out most users provided excellent feedback. For others they simply wanted an easy way to upgrade and move databases to new hardware. My former teammate, Jay Pearson, now a bigshot sales force with a tongue biting title, Engagement Manager manager, began bugging me to add features based on his customer’s feedback and provided a few good ideas. The popular filtering feature was from his request.
I can’t name how all of the ideas originated, but all ideas pretty much parachuted in by Fourth of July 2021. Daniele had a use case of merging three replica sets into a sharded cluster and I extended the idea to support migration while changing shard keys. The shard key change function also made migrating from a replica set to a sharded cluster possible. The reverse synchronization was already implemented in Shyam’s tool. The idea of having pause and resume functions was from, well, after seeing “Ctrl-Z” from a vehicle registration tag.
The detailed migration progress reporting feature was an invaluable addon to mongopush, but the feature came with a cost. Maintaining a large data structure of progress data required an excessive amount of memory usage. As a result the process was often killed by the kernel because of out of memory exceptions. I ended up moving the tasks status and progress data to a database and the detailed report generating function to a separate process. After decoupling the progress data from mongopush it made scaling easier.
Decoupling enabled adding additional workers outside the mongopush context and minions were introduced. With the ability to scale out the tool has evolved into an enterprise solution. However, while many users celebrated the ride of a possibility like Jack and Rose romantically gliding at the bow of a steamship (Titanic 1997), I was worried about whether the Titanic would hit the tip of an iceberg. Software is a double-sided blade that can improve productivity but also can have bugs that will bite. I needed to find time outside my day job to test more migrations for different use cases.
By Labor Day 2021 there were quite a few successful big data migration stories. About the same time I implemented Change Streams in mongopush and made live migration from DocumentDB and Cosmos DB possible. Before Thanksgiving 2021 a couple of successful Atlas migrations reported achieving almost 1TB hourly throughput, and both targeting destination clusters were on AWS. This was an important milestone. With proper resources and careful planning even migrating tens of terabytes can be completed in less than a weekend.
Selecting a tool was important, but planning properly was the key to success. From studying many migration results, proper planning ensures the success of an Atlas migration. My colleague Mike LaSpina has done a magnificent project migrating from 4 shards to 8 shards with a shard key change and achieved almost 1TB hourly throughput.
MongoPush is not for all use cases and, most importantly, is not designed to be a synchronization tool between two clusters for an extended period of time. The best practice is to cutover as soon as possible after initial data copy completes and oplog is caught up. You can beef up your resources and take advantage of mongopush’s parallelism to speed up the initial data migration. But when it reaches the oplog streaming phase, oplogs have to be applied sequentially or in the worst case one by one. Internally, mongopush optimizes oplogs streaming by grouping operations of the same collection together and writing in bulk. However, this requires each oplog to be unmarshaled and therefore is slower than simply copying raw documents during the initial data copy phase.
At the time that the Sun moves into Sagittarius, mongopush is ready for its v1.0 release.
Version 1.0
From the feedback I have gathered, I was determined to address the planning ignorance by adding additional preflight functions before releasing v1.0. Throughout my entire software career RTFM seemed to solve a lot of problems, but users were always too busy to read anything. In version 1.0 I enhanced the preflight function and it will do the following:
Execute a migration plan by reading configurations from a file
Verify configuration with a -testconfig function
Backwards compatible: generate configurations by reading pre-v1.0 command and write to a file
Enhance the -preflight function to check
Connectivity to all mongod processes and mongos if applicable
Source server version compatibility
Ensure source access roles
clusterMonitor role
clusterManager role if it’s a sharded cluster
readAnyDatabase role
Parse source connection string and recommend
Inflight compression (compressors=zstd,snappy)
Read preference (readPreference=secondaryPreferred)
Use of an index on a query filter if included
Target server version
Ensure target access role on Atlas has the atlasAdmin role
Ensure target access roles for self-maintained servers:
clusterMonitor
clusterManager if it’s a sharded cluster
readWriteAnyDatabase
Parse target connection string and recommend
Enable retryable writes (retryWrites=true)
Write concern (w=2)
Inflight compression (compressors=zstd,snappy)
Check if a metadata database is included if source is a sharded cluster
Check if the target Atlas instances are provisioned properly
Optionally clean up orphaned documents from the source cluster
The preflight function in v1.0 should provide recommendations to form a migration plan, but no migration plans are valid until they are validated by migrating to Atlas with a scaled down amount of data.
Having the function of reading configurations from a file, I added a Windows version for evaluation purposes. The supported operating systems are now Linux, macOS, and Windows. Using the Linux version for production migration is strongly recommended. Version 1.0 is scheduled for release on 1/2/2022, the birthday of Bùding, my puppy and the loyal mongopush cheerleader.
Transition To v1.0
Version 1.0 is mostly backward compatible except the removal of a couple of unused command line arguments. The new release only executes a migration plan by reading configurations from a file. Below is an example of a quickstart migration configuration file.
To transition from a previous version of mongopush simply execute the command as previously used using the new binary, for example:
After executing the above command a configuration file named mongopush-all.json will be created as below:
The next step is to run the preflight function to verify configurations and connectivity as follows:
The above command will print a list of recommendations. You can review them and update the configuration accordingly. The final step is to execute the migration plan as below:
After the migration completes, mongopush can validate the result by counting documents from both source and target and generate a comparison report. The command is as follows:
Note that mongopush literally counts documents using the countDocuments() function and thus to count large collections will take quite a while. In addition, because of oplogs streaming and applying, if there are writes, there will be discrepancy between the source and the target clusters.
Finally, to generate a detailed progress report, run the below command:
Experienced mongopush users may have noticed that all commands read from the same configuration file. This was the intention to simplify the format of possible commands. Snapshot file names are also changed and the host name is no longer part of the file name. Instead, mongopush uses a format of mongopush-<command>-snapshot.bson.gz and by default stores them under the directory snapshot.
To make all commands consistent, the resume function can also read from a configuration file, an example is as below:
Note that reading from a snapshot file is also supported.
Validation
To validate data consistency after a migration completes is a customized solution. The best option from available tools is the dbHash command. The limitation is that all writes have to be stopped and the command has to be executed against mongod processes. For a migration from and/or to a sharded cluster, the topology of the target cluster has to be a mirrored image of the source and the dbHash command is executed on each shard. With a large amount of data, this process can take a longer time than desired.
Realistically, stopping writes or having a suitable maintenance window to verify all collections in a timely manner is seldom an option. In that case, at a minimum, you can use the validation function from mongopush to count documents. Below is a sample output.
Source and target columns represent the number of documents in the collections as shown in the above sample output. The counted column shows the number of documents found during the collection splitting. If there is no insertion or deletion during the migration, the three numbers should be the same (line 2 and 3). Otherwise, from line 1, there were 3 additions to the db.dealers collection during the data migration.
If You Build It They Will Come
Although mongopush is my brain child, I have seldom recommended it to anyone if the Live Migration Service or mongomirror can do the trick. I knew that the development would be difficult because of limited resources. Users who chose to use mongopush were often as a last resort under extreme circumstances, such as needing a topology transformation, working around access issues blocked by private endpoints, shortening the migration time, or leaving historical data behind. Hopefully, mongopush can contribute to the success of your migration projects.
On the bright side, an officially supported migration tool will be available in the near future. After all, my throwing of a brick may have intrigued others to throw a jade. Until the rumored tool is available, enjoy mongopush as much as you can. Quoted from the movie Catch Me If You Can (2002), the FBI agent Hanratty once said “You have no one else to call”.
~ ken.chen@simagix.com


Comments