MongoPush - Push-Based MongoDB Atlas Migration Tool
MongoPush tool is another bold stroke in my serendipitous MongoDB career. It is a push based migration tool for MongoDB clusters. It provides high parallelism, supports topology transformation, is resumable, offers progress monitoring, and supports migrating subsets of data. With MongoDB Atlas gaining popularity and the success of the Keyhole, I was frequently asked whether a migration feature can be added to the Keyhole. The other existing migration solutions often fail because of firewall restrictions or other limitations. Keyhole serves a different purpose as an analysis tool, so rather than confuse its function, I created MongoPush as a separate tool.
Push-Based Solution
My goal was simple, to develop a tool that can perform a sharded cluster migration when the Atlas Live Migration Service is not suitable. MongoDB provides the mongomirror tool to push data to MongoDB Atlas from behind firewalls, but mongomirror can only migrate data between replica sets. It does not yet provide the migration of data between sharded clusters. This is the main problem which MongoPush solves.
The migration workflow of MongoPush can be summarized as the following steps: 1) automatic sharding configurations, 2) data migration, 3) index creation, and 4) oplogs streaming. Each of these occur sequentially but the processing within these steps is parallelised. While I was investigating existing solutions, additional challenges were brought up from my colleagues. The previous solutions for the migration of sharding clusters a combination of using a modified version of mongomirror and a number of execution steps. This approach has several limitations, specifically:
The source (donor) and target (receiving) clusters are required to have the same topology.
A large collection prolongs the migration time because of the sequentially processing nature of mongomirror
Not resumable
Limited progress monitoring
No data filtering available to migrate selective data
MongoPush does not suffer from these limitations.
Features Highlight
In this section, we discuss the implementation of how MongoPush overcomes the challenges typically encountered in the field with customers.
Topology Transformation Support
The source and the target clusters don’t have to have the same topology. The target cluster can be a sharded cluster or a replica set. If the target cluster is a sharded one, MongoPush connects to the mongos process to take advantage of its ability to distribute data to destination shards automatically. If the target cluster is a replica set and the source cluster is a sharded cluster, MongoPush can also handle merging the data to a single replica set. Below is an illustration of migrating from a 4 shard cluster to a 3 shard cluster.
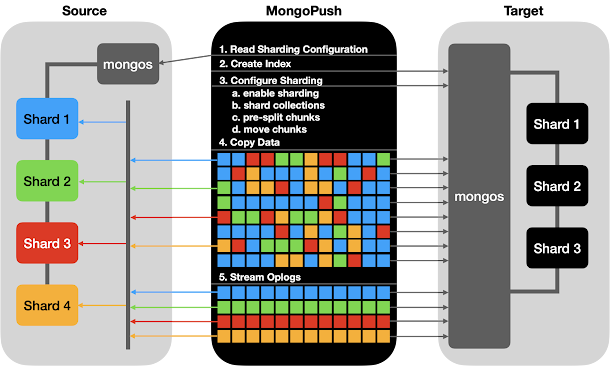
Automatic Configuration
If migrating to a sharded cluster, presplitting chunks is necessary to prevent target cluster performance degrading due to the required chunk moves. When MongoPush begins, it reads the sharding metadata information from the source cluster and applies it to the target cluster. This process includes several steps, and they are enabling sharding, sharding the collections, splitting the chunks and moving the chunks, respectively. This provides an identical shard and chunk distribution in the target cluster which avoids unnecessary chunk moves and chunk balancing during the later migration stages or once the migration completes.
High Parallelism
MongoPush is written in Go and uses many Keyhole’s functions. To achieve high parallelism, large collections are divided into smaller tasks. The tool uses two groups of threads (go func); one group to split large collections into small tasks and the other to perform data migration. After configuring the target cluster, MongoPush begins migrating data for small collections and splitting large collections into tasks. Once a collection split is done, tasks are added to the data migration queue and are then processed in due course.
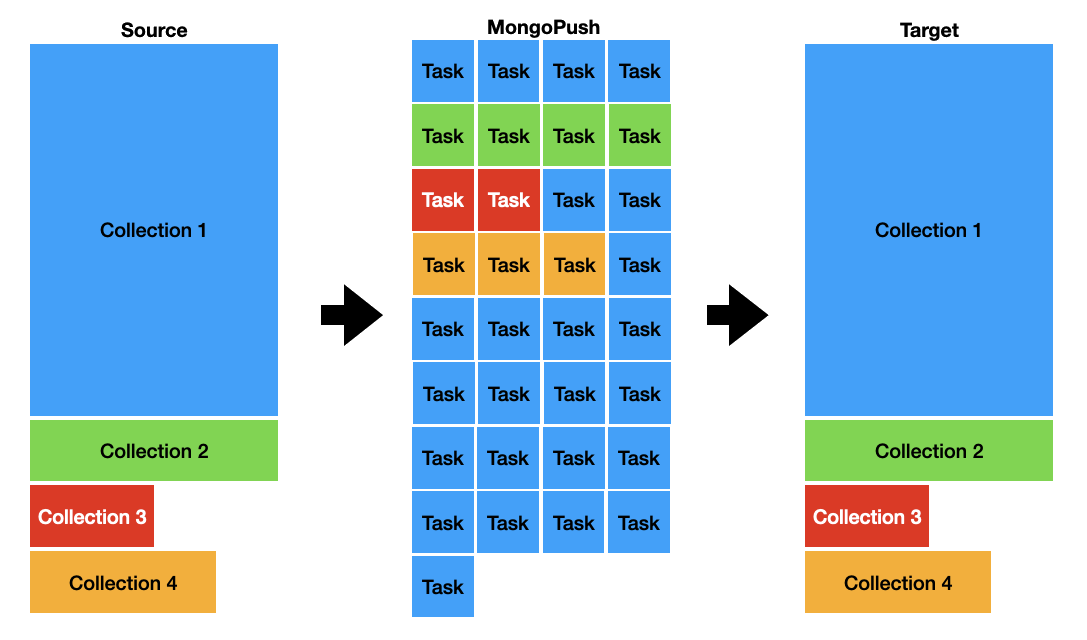
The above works makes resuming an Atlas migration and progress monitoring possible because MongoPush takes a snapshot of the source cluster’s original states. The snapshot file also holds the status of each migration task.
Resumable
With the original and migration progress states available, one can resume an interrupted migration manually from the persisted snapshot file. Moreover, the information from the snapshot can be used to audit a migration.
Monitoring
The migration progress viewing is available from a web browser. Below is an example of the overall migration status:

Selective Data Migration
It is recommended that unneeded data is purged from the source cluster before migration to reduce the overall data transfer time. Typically, in the real-world customers want to keep as much as possible of this data, perhaps, for analytics or reporting purposes. MongoPush allows for selective data migration through the definition of namespaces and/or queries. This feature makes the merging of multiple clusters into one Atlas cluster or the splitting of an existing cluster into multiple Atlas clusters possible.
Flexibility
MongoPush can perform configuration stages and data transfers in one step, but it also allows for these steps to be performed separately. A possible migration use case is where the shard key for a collection will be changed after migrating to Atlas. In this case, one will have to manually configure sharding information and only use MongoPush to transfer the data to Atlas.
Final Words
To migrate big data to MongoDB Atlas is a time consuming task. I hope this provides a helpful guide to assist your Atlas migration project. See my other blogs, Exploring MongoPush Using a Case of Filtering and Rename, Change Shard Key and Migrate to Atlas Using MongoPush, MongoPush Your GridFS to Atlas, Planning MongoPush Atlas Migration, and Scaling MongoPush With Minions for migration use cases.
~ ken.chen@simagix.com


Comments